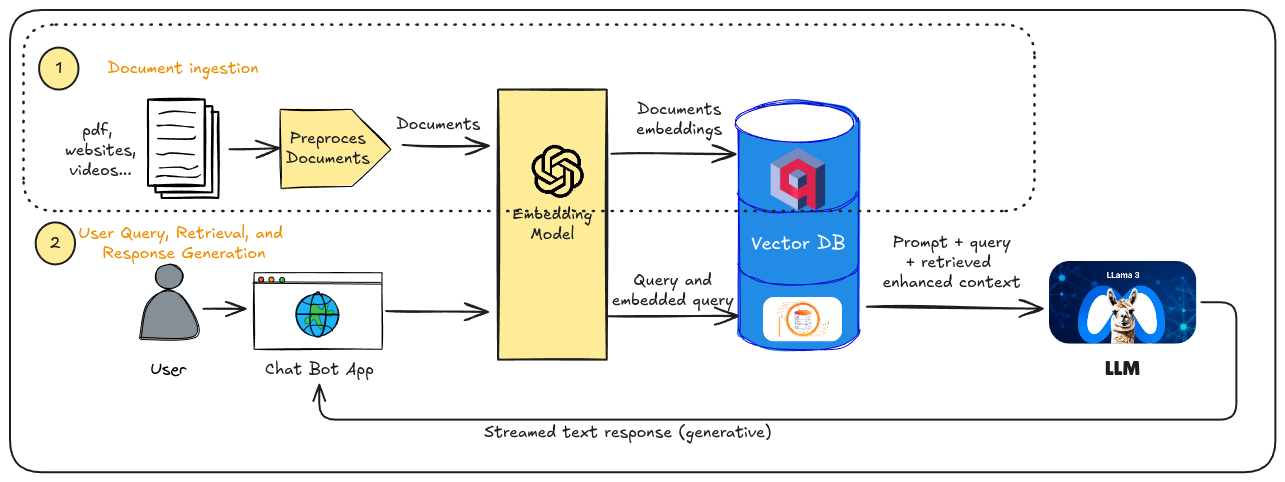
Tutorial: First Step in a RAG pipeline, Data Ingestion (Part 2) - Databases Configuration.
Before we can store our data, we need to set up the two databases we’ll be using in this tutorial: the vector database hosted by Qdrant and the CloudFlare D1 database. As mentioned in the previous part of this tutorial, you must create an account for both of these platforms. Let’s get started.
Creating a Qdrant Database
The steps for creating a Qdrant database are straightforward. After creating your account, you need to create a cluster and then generate an API key to interact with the cluster from another application.
A free-tier cluster includes a single node with the following resources:
| Resource | Value |
|---|---|
| RAM | 1 GB |
| vCPU | 0.5 |
| Disk space | 4 GB |
| Nodes | 1 |
This configuration supports serving about 1 M vectors of
The steps to create a Qdrant Cloud cluster are the following:
- Start in the Clusters section of the Cloud Dashboard.
- Select Clusters and then click + Create.
- In the Create a cluster screen select Free.
- When you’re ready, select Create. It takes some time to provision your cluster.
After creating the cluster, the page will automatically guide you to the API key creation process. Be sure to save this key in a secure location and avoid sharing it with anyone, as we’ll need it for later use.
Library to Manage Qdrant Database
To streamline interactions with the Qdrant database, I’ve created a utility script in TypeScript named qdrant.ts. To begin using the Qdrant API, we must install the @qdrant/js-client-rest npm package:
npm install @qdrant/js-client-restOnce installed, we can import the QdrantClient class into our script and define the data point type that will be stored in the database.
1import { QdrantClient } from "@qdrant/js-client-rest";2
3export type Point = {4 id: number;5 vector: number[];6 payload?: Record<string, unknown>;7};Finally, I’ve exported a utility class called QdrantDatabase containing all the necessary functions for managing our database.
1export class QdrantDatabase {2 readonly collectionName: string;3 readonly vectorSize: number;4 private client: QdrantClient;5
6 constructor(collectionName: string, vectorSize: number) {7 this.collectionName = collectionName;8 this.vectorSize = vectorSize;9 this.client = this.createClient();10 this.createCollection();11 }12
13 private createClient() {14 const client = new QdrantClient({15 url: process.env.QDRANT_URL,16 apiKey: process.env.QDRANT_API_KEY,17 });18 return client;19 }20
21 private async createCollection() {22 const response = await this.client.getCollections();23 const collectionNames = response.collections.map((collection) => collection.name);24
25 if (collectionNames.includes(this.collectionName)) {26 // await this.client.deleteCollection(this.collectionName);27 return;28 }29
30 await this.client.createCollection(this.collectionName, {31 vectors: {32 size: this.vectorSize,33 distance: "Cosine",34 },35 optimizers_config: {36 default_segment_number: 2,37 },38 replication_factor: 2,39 });40 }41 ...42}The constructor of this class accepts the name of the collection to be created, allowing you to create multiple collections if needed. It also takes the size of the vector to be stored in that collection. We’ll be using a vector size of createClient method, which is used for all interactions with the vector database. To create the client, you’ll need the API key and cluster URL provided during the creation process described in the previous section. The constructor also creates the collection to store the vectors if it doesn’t already exist with the specified name, using the createCollection method.
Finally, the class includes two additional methods: addPoints for storing points in the database and search for conducting similarity searches for a query vector within the database:
1export class QdrantDatabase {2 ...3 async addPoints(inputPoints: Point[]) {4 await this.client.upsert(this.collectionName, {5 wait: true,6 points: inputPoints,7 });8 }9
10 async search(query: number[], resultsLimit: number) {11 return await this.client.search(this.collectionName, {12 vector: query,13 limit: resultsLimit,14 });15 }16
17}Create a CloudFlare D1 database and a table to store the text
We’ll use Node.js to create and configure our CloudFlare D1 database. Before we begin, you’ll need to choose either a CloudFlare Worker or a CloudFlare Page for your project, depending on your specific needs.
In this separate tutorial, I explain how to create a project with AstroJS and Cloudflare Pages: link to AstroJS documentation.
Now, let’s create a database within your project using the following command:
npx wrangler d1 create rag-databaseThe first time you run this command, it will open your browser to prompt you to log in to your CloudFlare account. I’ve named the database rag-database, but feel free to choose a different name if desired. This command will also generate the following lines in your terminal with a valid ID:
[[d1_databases]]binding = "DB" # available in your Worker on env.DBdatabase_name = "prod-d1-tutorial"database_id = "<unique-ID-for-your-database>"Copy these lines into your wrangler.toml configuration file, which was created when you initialised the project with Wrangler. We’ll use the database ID to connect to the database later.
Finally let’s create a table. In this application, we’ll create a notes table in D1, which will allow us to store notes and later retrieve them with the ID field stored in Qdrant. To create this table, run a SQL command using wrangler d1 execute:
npx wrangler d1 execute rag-database --remote --command "CREATE TABLE IF NOT EXISTS notes (id INTEGER PRIMARY KEY, text TEXT NOT NULL)"Finally, you can also test the database by adding one entry to your table:
npx wrangler d1 execute rag-database --remote --command "INSERT INTO notes (text) VALUES ('The best pizza topping is pepperoni')"Generate a CloudFlare API token
Before moving on to the next part, it’s necessary to create an API token for making calls to the CloudFlare D1 and Workers AI APIs.
To create the token, navigate to the “My Profile” page, which is located in the drop-down menu when you click on the user logo in the top right corner of the CloudFlare dashboard. Once there, go to “API Tokens” and select “Create Token.” Assign a desired name to the token and add the following permissions:
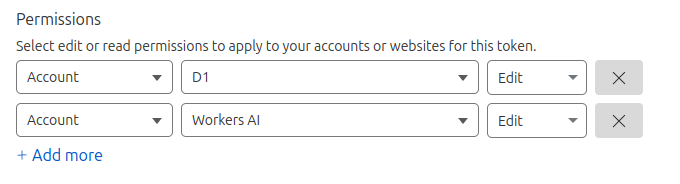
After completing the remaining steps, securely store the API token in a private location. We’ll use it in the next part of the tutorial.
Now that we’ve completed the setup, we’re ready to start storing our processed data in both databases. Let’s see how to do that in the next part of this tutorial.